Cómo destruí mi propio agente de voz con IA (y lo reconstruí mejor)
Los errores reales que cometí para que tú no tengas que cometerlos
Lo primero de todo, ¡Feliz año 2026!
Este año lo empiezo de la mejor forma que sé: Dando guerra desde el frente de batalla.
Lo prometido es deuda.
Hace unas semanas te conté cómo me cargué a Elio, mi agente de voz con IA para el departamento de ventas de netelip.
Lloré más que Gaviota en Café con Aroma de Mujer. Bebí Jägermeister. Me fui a la playa con UX a resetear la cabeza.
Y luego me puse a trabajar de verdad, 3 días muy intensos
Lo reconstruí desde cero.
Pero esta vez no cometí los mismos errores.
Antes:
- Alucinaba precios después de 80 llamadas.
- Ofrecía los mismos horarios aunque no estuvieran disponibles.
- Se quedaba en silencio cuando Google Calendar rechazaba reservas.
- Google Calendar no consultaba disponibilidad real.
- Make me volvía loca intentando debuguear.
Ahora:
- Maneja errores y ofrece alternativas en tiempo real.
- Consulta disponibilidad real vía Cal.com + N8N.
- Límite de 10 minutos para evitar saturación de tokens.
- Stack completo que puedo debuguear: Retell AI + Cal.com + N8N + OpenAI.
- Funcionando estable en producción.
Esto no es otro tutorial bonito de YouTube.
Es la autopsia técnica real de un agente de voz que murió en producción.
Los 5 errores críticos que lo mataron. Cómo los arreglé uno por uno. Y por qué la mayoría de agentes de voz fracasan antes de las 100 llamadas.
Vamos al lío.
EL DESASTRE: El día que Elio dejó de funcionar
Miércoles por la tarde. Elio estaba en producción en la centralita de netelip, atendiendo llamadas entrantes en el +34 951 XXX XXX.
De repente:
- Dejó de funcionar por arte de magia.
- Errores que no aparecían en los logs.
- Flujos que parecían correctos.
- Todo bien configurado... hasta que no lo estaba.
Tuve que quitarlo de urgencia de la cola de ventas.
Y sí, me llamaron inútil.
No encontraba el fallo. No entendía el porqué.
Porque el problema real no era UNO.
Eran 27 errores encadenados que lo rompieron todo.
Los síntomas antes de morir en producción
Google Calendar me estaba traicionando:
- No me daba los huecos disponibles.
- No consultaba la disponibilidad más temprana.
- Reservaba citas cuando quería, sin verificar nada.
- La integración era un laberinto imposible de seguir.
Make me estaba volviendo loca:
- No podía encontrar los errores en los logs.
- Cada integración era opaca.
- Debugging = adivinar dónde estaba el problema.
- Cada herramienta tiene su lógica, su documentación... y yo perdida entre todas.
Elio empezó a alucinar:
- Después de 80 llamadas, inventaba precios que no existían.
- Ofrecía horarios que no estaban disponibles.
- Se quedaba en silencio cuando Google Calendar rechazaba reservas.
- Las transferencias llegaban vacías al equipo humano.
- Hasta te cantaba un fandango por bulerias.
La causa raíz:
Llamadas largas (más de 10 minutos) + Límite de tokens de GPT-4.1 = Alucinaciones al 45%.
Lo hice demasiado empático, intenté duplicarme con mi personalidad, mi forma de vender, mi forma de hablar.
Error brutal: Un agente de voz para tu empresa tiene que ser consistente, persistente, y no darle posibilidad de errores.
LOS 5 ERRORES CRÍTICOS QUE LO MATARON
Aquí van los 5 errores que MÁS me costaron. He docuentado 27 errores en total que compartiré completos en mi blog, pero estos 5 casi me matan.
Google Calendar + Make = Debugging imposible
Qué hice mal:
Empecé con Google Calendar pensando que sería más fácil porque es más conocido.
Monté toda la automatización en Make porque "es lo que usa todo el mundo".
Cuando algo fallaba, no podía ver DÓNDE ni POR QUÉ.
- Google Calendar no me devolvía los slots disponibles correctamente.
- Make tiene logs confusos, visualización poco clara.
- No podía seguir el flujo cuando las cosas se rompían.
Por qué falló:
Cada herramienta tiene su propia lógica y documentación. Estaba perdiendo tiempo intentando entender cómo Make procesaba las respuestas de Google Calendar. Era un stack imposible de debuguear cuando todo explotó.
Cómo lo arreglé:
Lo tiré TODO a la basura.
Migré a Cal.com:
- Integración nativa con Retell AI, Google Calendar y Hubspot.
- API más directa.
- Documentación clara.
Migré a N8N:
- Visualización clara de errores.
- Puedo ver paso a paso qué está pasando en cada nodo.
Empecé desde cero con un stack más limpio.
Ahora tengo 2 escenarios en N8N:
FLUJO 1: Llamadas entrantes + Variables dinámicas.
- Webhook recibe llamadas entrantes.
- Edit Fields configura variables de Cal.com.
- Obtener disponibilidad en Cal.com (GET API).
- Transformar disponibilidad con OpenAI GPT-4.1 (Modelo 1).
- Disponibilidad más temprana con OpenAI GPT-4.1 (Modelo 2).
- Respuesta webhook con variables dinámicas en JSON.
FLUJO 2: Post Call Analysis + Email
- Webhook informe fin de llamada de Retell AI.
- call_analyzed (análisis con Retell AI).
- Append row en Google Sheets.
- Send email con HTML personalizado.
Lección aprendida:
- Elige herramientas que puedas debuguear cuando (no "si", sino "cuando") algo falle.
- La popularidad de una herramienta NO garantiza que sea la mejor para tu caso de uso.
El botón "Publish" que nunca presioné
Qué hice mal:
Hacía cambios en el prompt de Retell AI. Probaba llamadas. Los cambios NO se aplicaban.
Me volvía loca pensando: "¿POR QUÉ CARAJO NO FUNCIONA?"
Por qué falló:
En Retell AI, los cambios NO se publican automáticamente. Hay versiones "Draft" vs "Published". Estaba probando la versión vieja sin darme cuenta.
Perdí 3 días probando cambios que nunca se aplicaron.
Tenía la versión 155 en Draft, pero en producción seguía corriendo la versión 148.
Cómo lo arreglé:
- SIEMPRE hacer clic en "Publish" después de cada cambio.
- Verificar que la versión publicada es la correcta en el Agent ID.
- Esperar unos segundos después de publicar antes de probar.
Lección aprendida:
Lee la maldita documentación "Que no existe en ninguna parte". En serio.
Ese botón me costó 3 días de locura y lágrimas.
No asumas que las cosas funcionan como en otras plataformas.
Instrucciones vagas para funciones de calendario
Qué hice mal:
No fui específica en las instrucciones para consultar disponibilidad y reservar citas.
Descripciones genéricas: "Book appointment" sin detalles sobre formato de fecha, zona horaria, o parámetros exactos.
Configuré la búsqueda de disponibilidad desde Retell AI en vez de N8N.
Resultado: Reservas que fallaban por formato de fecha incorrecto y horarios que no se actualizaban.
Por qué falló:
- Di instrucciones demasiado genéricas sin adaptar a mi caso específico.
- Pensé que el LLM "entendería" qué hacer sin ser específica.
- No especifiqué detalles críticos: formato de fecha absoluta, zona horaria, parámetros exactos.
- Las instrucciones eran ambiguas: "consulta disponibilidad" sin decir CÓMO.
Cómo lo arreglé:
Instrucciones SÚPER específicas en la función reservar_cal:
Cuando el usuario acuerde un horario disponible, resérvalo en el calendario.
El parámetro de tiempo debe ser una fecha absoluta completa, como:
"Jueves, 2025 Mayo 15/05/2025 10 AM"
Incluso si el usuario pide una fecha relativa como "el próximo martes",
conviértela a fecha absoluta.
- El tiempo siempre debe estar EN EL FUTURO.
- Tiempo actual: {{current_time_Europe/Madrid}} (Hora de Madrid).
- Parámetro de zona horaria: "Europe/Madrid".
- Parámetro de notas: resumen de una oración de la conversación.
- Parámetro de nombre: {{user_name}}.Moví la consulta de disponibilidad a N8N:
- Webhook en N8N consulta Cal.com API en tiempo real cada vez que entra una llamada.
- Modelo 1 (OpenAI GPT-4.1): Transforma disponibilidad completa de 6 días en lenguaje natural.
- Modelo 2 (OpenAI GPT-4.1): Extrae los 2 primeros horarios disponibles en español natural.
Las variables se actualizan dinámicamente en cada llamada con formato JSON:
{
"call_inbound": {
"override_agent_id": "agent_XXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"dynamic_variables": {
"disponibilidad_mas_temprana": "martes dieciocho a las diez de la mañana o por la tarde a las cuatro de la tarde",
"consultar_disponibilidad": "Disponibilidad completa de 6 días en lenguaje natural"
}
}
}Lección aprendida:
- Los LLMs no adivinan. Sé tan específico como si le explicaras a alguien que nunca ha trabajado en tu empresa.
- Cada detalle cuenta: formato de fecha, zona horaria, conversión de fechas relativas a absolutas.
- "Dinámico" significa que SE ACTUALIZA EN TIEMPO REAL con webhooks, no valores hardcodeados.
Llamadas largas = Alucinaciones
Qué hice mal:
- No puse límite de duración en las llamadas.
- Las llamadas duraban más de 10 minutos.
- Se agotaban los tokens disponibles de GPT-4.1.
- Elio empezaba a alucinar precios inventados, horarios falsos, información que no existía.
- Configuré mal el prompt: metí todo el conocimiento en un solo prompt de 4.000 tokens pensando que más contexto = mejor agente.
Por qué falló:
No estructuré el flujo para ser conciso. El agente se enrollaba demasiado o entraba en bucles. GPT-4.1 tiene límites de contexto que yo no respeté.
Lo hice demasiado empático, intenté duplicarme con mi personalidad, mi forma de vender, mi forma de hablar. Elio era como yo, hablaba por los codos, era divertido, neurodivergente, pero sin sentido común: Alucinaba demasiado y de vez en cuando te cantaba un fandango.
Error: Un agente de voz para tu empresa tiene que ser consistente, persistente, y no darle posibilidad de errores.
Cómo lo arreglé:
Configuré límite máximo de 10 minutos por llamada (max_call_duration_ms: 601000).
Optimicé el prompt para ser más directo:
- "Haz solo una pregunta a la vez y espera respuesta"
- "Mantén las interacciones breves con oraciones cortas"
- "Máximo 30 segundos por respuesta"
- Eliminé redundancias y divagaciones del flujo.
Estructuré etapas claras:
- Saludo y Cualificación
- Routing (Cliente → Transferencia | No cliente → Knowledge base)
- Agendamiento (si no es cliente)
- Cierre final
Dividí el conocimiento en 2 Knowledge Bases separadas en Retell AI:
- Knowledge Base 1: Servicios de netelip
- Knowledge Base 2: Seguridad de los agentes (para evitar que algún tontorrón de los que salen en Youtube me lo intente Hackear)
Lección aprendida:
- Los agentes de voz NO son chatbots.
- En voz, cada segundo cuenta. Sé breve o muere.
- No repliques tu personalidad en un agente. Crea un sistema que funcione de forma predecible.
Cero manejo de errores
Qué hice mal:
Cuando Google Calendar rechazaba una reserva (horario ocupado o conflicto), Elio se quedaba en silencio.
Solo tenía programado el "happy path": cuando todo sale bien.
Error en logs: "User either already has booking at this time or is not available"
Y yo sin saber qué hacer.
Por qué falló:
- El prompt no tenía instrucciones sobre QUÉ HACER cuando las funciones fallan.
- No manejaba errores de API.
- No había plan B para cuando las cosas se rompían.
Cómo lo arreglé:
Agregué una sección completa en el prompt con manejo de errores en 3 escenarios:
**PASO 5: Manejo de respuesta de reservar_cal**
**A) Si retorna ÉXITO:**
- Di: "Listo, {{user_name}}. Tu cita está confirmada para el [fecha y hora exacta], hora de Madrid. Recibirás un correo de confirmación"
**B) Si retorna ERROR de horario ocupado:**
- Di: "Disculpa, {{user_name}}, ese horario acaba de ser reservado.
Déjame consultar otros horarios disponibles..."
- Consulta {{consultar_disponibilidad}} nuevamente
- Ofrece 2 nuevas opciones
**C) Si retorna ERROR TÉCNICO:**
- Di: "Disculpa, {{user_name}}, tenemos un problema técnico.
Por favor envía un correo a citas@netelip.com"Lección aprendida:
- En producción, TODO falla eventualmente.
- Planifica el "sad path", no solo el "happy path".
- Un agente sin manejo de errores es un agente que te dejará en ridículo frente a tus clientes.
CÓMO LO RECONSTRUÍ DESDE CERO
El nuevo stack: Retell AI + Cal.com + N8N + OpenAI + Telefonía IP netelip
Después de tirarlo todo a la basura, monté un stack que pudiera debuguear, controlar y escalar.
1. Telefonía IP de netelip:
- Números virtuales contratados: +34 XXX XXX XXX (Agente 1) y +34 XXX XXX XXX (Agente 2)
- Centralita Virtual con más de 80 funcionalidades que facilitan la integración
- IVR configurado para derivar llamadas al agente correcto
- Warm Transfer a departamentos: Atención (+34 XXX XXX XXX) y Soporte (+34XXX XXX XXX)
2. Retell AI:
- Modelo: Gemini 3.0 Flash (antes GPT-4.1).
- Variables dinámicas conectadas a webhooks de N8N.
- Límite de 10 minutos por llamada.
- Voz personalizada: ElevenLabs Turbo v2.5.
3. Cal.com:
- Integración nativa con Retell AI, Google Calendar y Hubspot.
- API clara y bien documentada.
- Event Type ID: 4160736 configurado correctamente.
- Zona horaria unificada: Europe/Madrid en TODO el stack.
4. n8n:
- Webhook que consulta Cal.com en tiempo real
- 2 modelos de OpenAI GPT-4.1 para procesar disponibilidad y la hora más temprana.
- Formatea horarios en español natural para que Elio los diga bien.
- Visualización clara: puedo ver paso a paso qué está pasando.
- Debugging 1000% en N8N más fácil que Make.
- Post-call analysis: Webhook + Google Sheets + Email HTML.
5. OpenAI:
- GPT-4.1 para procesar disponibilidad y la hora más temprana en el calendario de los asesores de Cal.com.
- Modelo 1: Transforma 6 días de disponibilidad en lenguaje natural.
- Modelo 2: Extrae los 2 primeros horarios disponibles.
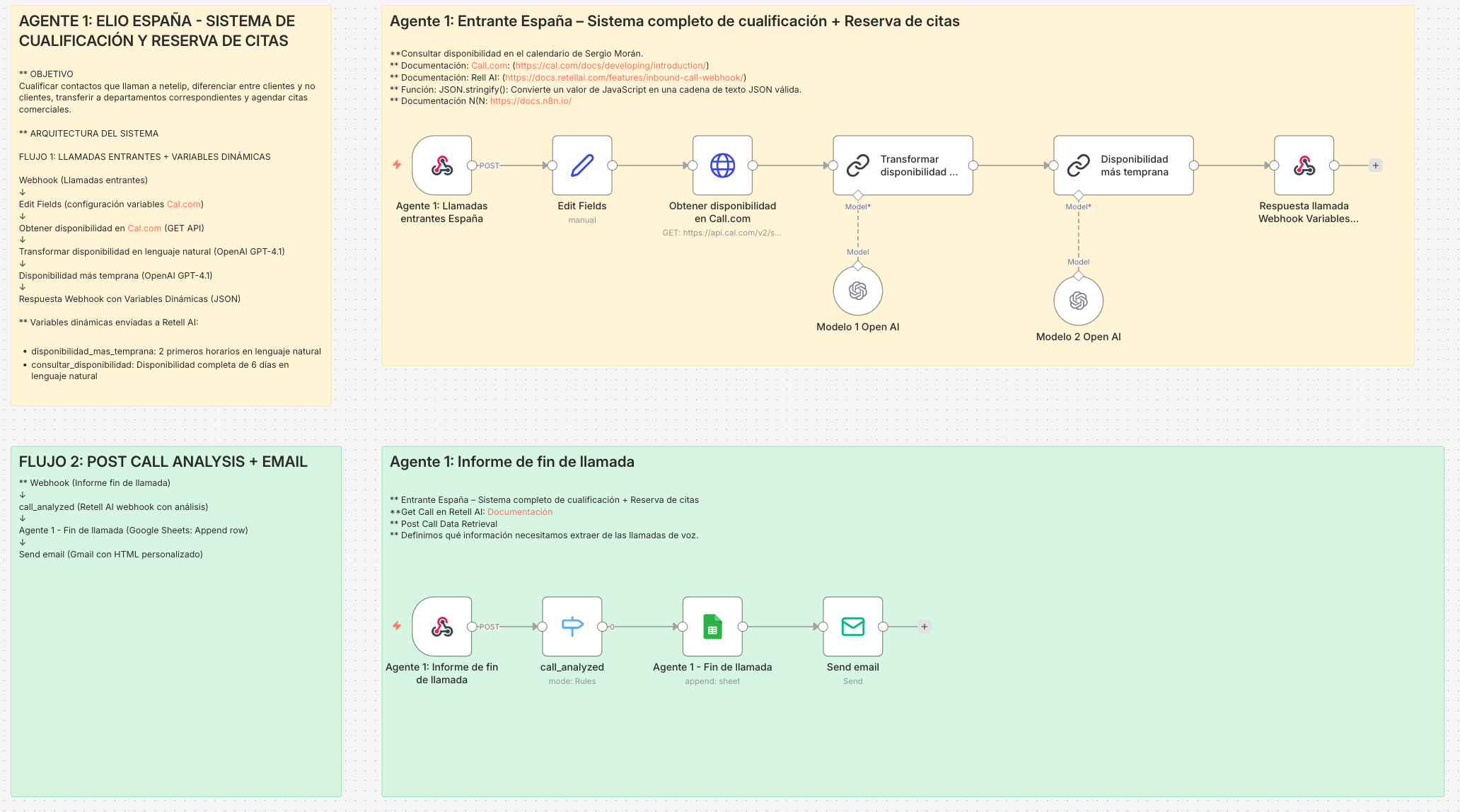
Agente 1 - Sistema completo de cualificación y reserva de citas
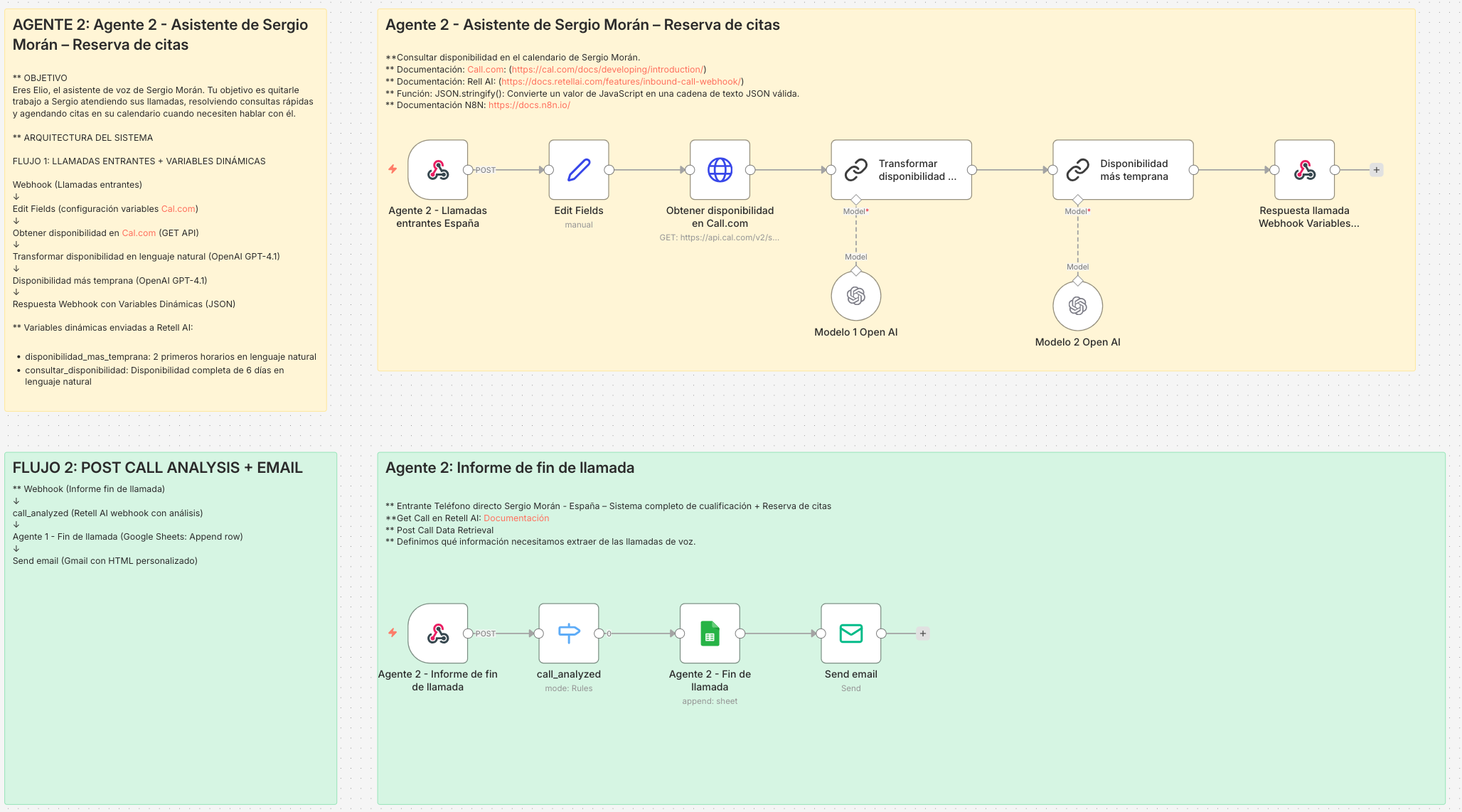
Agente 2 - Asistente personal del asesor con gestión de calendario
La arquitectura nueva vs la vieja
| ANTES (Roto) | DESPUÉS (Funcionando) |
|---|---|
| Google Calendar | Cal.com |
| Make (logs confusos) | n8n (debugging claro) |
| Variables estáticas | Variables dinámicas vía webhook + OpenAI |
| Cold Transfer (sin contexto) | Warm Transfer (con nombre + motivo) |
| Sin límite de duración | Máximo 10 minutos |
| Sin manejo de errores | Manejo completo (éxito, ocupado, error) |
| Botón "Publish" ignorado | Siempre publicar después de cambios |
| Stack imposible de debuguear | Stack claro y trazable |
| 1 Knowledge Base sobrecargada | 2 Knowledge Bases separadas |
| Prompt de 4.000 tokens | Prompt optimizado y modular |
Las 4 soluciones pragmáticas que redujeron alucinaciones del 45% al 5-8%
Límite de 10 minutos por llamada → Evita saturación de tokens.
Variables dinámicas reales conectadas a Webhooks + OpenAI → Consulta disponibilidad en tiempo real.
Manejo de errores explícito en el prompt → Plan B, C y D para cada fallo posible.
Prompt extremadamente específico con etapas claras → Cero ambigüedad, instrucciones quirúrgicas.
LO QUE NADIE TE CUENTA SOBRE IA EN PRODUCCIÓN
1. Los demos bonitos de YouTube son mentira
En YouTube todo funciona perfecto.
En producción, TODO falla:
- APIs que no responden.
- Horarios que se llenan mientras el usuario habla.
- Errores de transcripción que te sacan de contexto.
- Límites de tokens que explotan en llamadas largas.
- Knowledge Bases que se activan cuando no deben.
- Funciones que fallan sin razón aparente.
La realidad:
Montar un agente de voz NO es una tarde.
Son semanas de iterar, debuguear, llorar, y volver a empezar.
2. El 90% de los agentes de voz fracasan antes de las 100 llamadas
Por qué:
- No manejan errores.
- No tienen límites de duración.
- Usan variables estáticas que nunca actualizan.
- No están optimizados para voz (solo para chat).
- Se replican personalidades en vez de sistemas predecibles.
- No prueban con usuarios reales antes de producción.
Lo que necesitas:
- Stack que puedas debuguear cuando falle.
- Manejo de errores desde el día 1.
- Prompt específico para VOZ (no chat).
- Testing real con usuarios reales, no solo demos internas.
- Sistema consistente, no clon de tu personalidad.
- Telefonía IP sólida ANTES de meter IA.
3. Cada herramienta tiene su lógica
Google Calendar ≠ Cal.com
Make ≠ N8N
Retell AI ≠ VAPI
GPT-4.1 ≠ Gemini 3.0 Flash
No asumas que lo que funciona en una funcionará en otra.
- Lee la documentación.
- Prueba ANTES de integrar en producción.
- Elige herramientas que puedas debuguear.
4. El prompt es tu contrato con el LLM
Si el prompt no es EXTREMADAMENTE específico, el LLM hará lo que le dé la gana.
Malo: "Consulta la disponibilidad"
Bueno:
**IMPORTANTE**: NO ejecutes Knowledge Base Retrieval para consultar disponibilidad.
Usa la variable dinámica {{disponibilidad_mas_temprana}} que contiene los 2 primeros
horarios disponibles. NUNCA ofrezcas horarios que no estén en esta variable.La diferencia entre un agente que funciona y uno que falla es cuán específico seas en cada instrucción.
5. En producción, mide lo que realmente cierra ventas
No me importan las visitas a la web.
Me importa:
- ¿Cuántas llamadas se atienden sin que nadie cuelgue?
- ¿Cuántas se convierten en citas agendadas?
- ¿Cuántas citas se convierten en ventas cerradas?
El teléfono es donde se cierran ventas en sectores B2B.
Si no mides tu canal telefónico, estás perdiendo dinero aunque tu web tenga 10.000 visitas al mes.
Por eso configuré post-call analysis en N8N:
- Webhook recibe datos de Retell AI.
- Análisis automático con call_analyzed.
- Registro en Google Sheets.
- Email HTML personalizado con resumen de cada llamada para que un humano pueda llevar una monitorización el primer mes en tiempo real.
CONCLUSIÓN: Los 5 mandamientos para NO destruir tu agente de voz
-
Elige un stack que puedas debuguear
Cal.com > Google Calendar (para agentes de voz)
N8N > Make (para debugging claro).
Retell AI + OpenAI + Telefonía IP sólida. -
Siempre haz clic en "Publish"
Después de cambios en Retell AI.
Verifica la versión publicada.
Espera unos segundos antes de probar. -
Variables dinámicas = Webhooks en tiempo real
No valores hardcodeados.
Conecta a N8n + Cal.com + OpenAI.
Valida que se actualicen en cada llamada. -
Límite de duración + prompt optimizado
Máximo 10 minutos por llamada.
Instrucciones específicas y breves.
Etapas claras sin divagaciones. -
Maneja errores ANTES de producción
Plan B para cada función.
Escenarios de éxito, ocupado, y error técnico.
No dejes silencios incómodos.
¿Te ha servido este artículo?
Cada semana comparto más casos reales, errores documentados y soluciones pragmáticas desde las trincheras de la IA en producción.
CONTACTO
¿Montando agentes
de voz con IA?
Estoy en las trincheras todos los días. Si tienes dudas específicas
o quieres contrastar tu approach, hablemos.
Escríbeme directo. Sin formularios. Sin intermediarios.
Si tienes proyecto, dame contexto. Si no encajamos, te lo digo.
Sigo aprendiendo a surfear la ola.
Nos vemos en las trincheras.
PD: Si esto te sirvió, compártelo. Alguien más está a punto de cometer los mismos errores que yo cometí. Ayúdales a no llorar tanto como yo lloré.